Why Your First Commit on Any Fork Should Be a License Audit
Most developers glance at LICENSE files and move on. After auditing what looked like an Apache-2.0 fork — and finding every file marked proprietary — I built a five-minute SPDX checklist.
Why Your First Commit on Any Fork Should Be a License Audit
A retrospective on SPDX, Apache-2.0, and the upstream Apache-2.0 fork I nearly shipped
This is Part 3 of the Open-Source Commerce-AI series. In Part 1, I connected an upstream multi-agent blueprint to Shopware 6. In Part 2, I swapped the LLM and debugged the fallout. Today: the license header that reset my roadmap — and the five-minute audit that would have caught it.
I had a working demo. Five agents, live Shopware data, product images rendering correctly, a fix for Llama 4 Maverick's verbose routing. A potential partner had seen it. We were talking pricing.
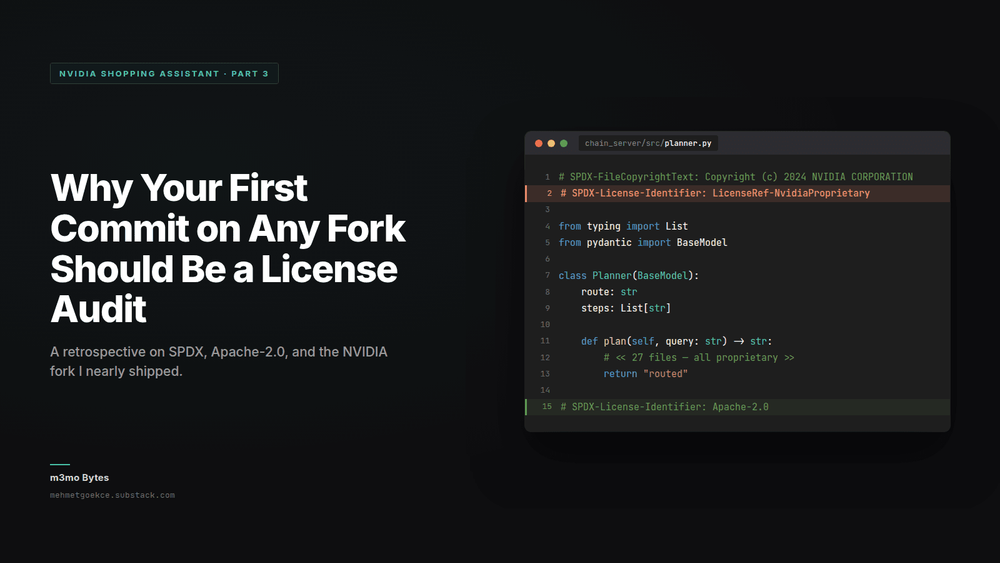
Then I opened chain_server/src/planner.py and saw this:
Every file. All 27 Python source files. NVIDIA proprietary license.
The demo worked. The tech was solid. And none of it was mine to sell.
What SPDX Headers Actually Mean
SPDX — Software Package Data Exchange — is the industry standard for communicating license information in source files. When you see SPDX-License-Identifier at the top of a file, it's not a suggestion. It's a legally binding declaration of the terms under which you can use that code.
Most developers glance at the LICENSE file in the repo root and move on. That's a mistake. Here's why:
A repository can have a permissive license at the root level — say, MIT or Apache-2.0 — while individual files carry different SPDX identifiers. This is common in large projects where some components were contributed under different terms, or where the project evolved from a proprietary codebase.
The SPDX header on the file you're modifying is the one that governs your rights to that file. Not the root LICENSE. Not the README's license badge. Not the GitHub sidebar.
Three files in the same repo, three completely different legal obligations.
The Five-Minute License Audit
After the NVIDIA experience, I developed a checklist I now run on every fork before writing a single line of code. It takes five minutes. Skipping it can cost months.
Step 1: Check the Root License
Look for the license name. Apache-2.0, MIT, and BSD-3-Clause are generally safe for commercial use. GPL requires open-sourcing your modifications. Proprietary licenses need individual review.
But don't stop here.
Step 2: Scan SPDX Headers
This gives you every unique SPDX identifier in the codebase. If they're all the same and match the root license — you're clear. If you see mixed identifiers, you need to understand which files you're touching.
Step 3: Check for Copyright Assignments
Copyright text tells you who owns the code. Even under permissive licenses, some copyright holders include additional restrictions in their contributor agreements that aren't visible in the SPDX header.
Step 4: Read the NOTICE File
Many Apache-2.0 projects include a NOTICE file with attribution requirements. Unlike MIT (where attribution is minimal), Apache-2.0 requires you to include the NOTICE file in your distribution. If the NOTICE includes restrictions beyond the license, those apply too.
Step 5: Check for Patent Grants
Apache-2.0 includes an explicit patent grant — contributors license their relevant patents to you. MIT does not. If you're building on patented technology (common in AI/ML), the patent clause matters.
For AI projects using models and algorithms that may be patented, Apache-2.0's patent grant is a meaningful protection.
Real-World Scenarios
Scenario 1: The Demo That Can't Ship
You fork an AI blueprint. The root LICENSE says "Sample Code License." The SPDX headers say LicenseRef-NvidiaProprietary. You build a demo, show it to a client, they want to buy.
You can't sell it. The license allows evaluation and demonstration, not redistribution or commercial deployment. Your options: license the technology from the owner (if they offer that), or rewrite from scratch using only the ideas — not the code.
A clean-room rewrite means: new file structure, new variable names, new implementation approach. You can use the same algorithms (ideas aren't copyrightable), but you can't reference the original code while writing. Two teams: one reads the original, documents the behavior. A different team implements from the documentation.
Estimated cost for a 4,500-line multi-agent system: weeks of work.
Scenario 2: The Permissive Fork
Same AI framework, different license. Root LICENSE is Apache-2.0. Every SPDX header confirms Apache-2.0. No NOTICE file restrictions beyond standard attribution.
You fork, modify, rebrand, deploy commercially. You must:
- Include the original LICENSE file
- Include the NOTICE file (if present)
- State changes you made
- Not use the original project's trademarks
You don't have to:
- Open-source your modifications
- Share your proprietary additions
- Pay royalties
This is the difference between a $30K rewrite and a weekend of integration work.
Scenario 3: The GPL Trap
An open-source e-commerce plugin is licensed under GPL-3.0. You integrate it into your commercial SaaS product. Under GPL, your entire product — every file that links to or imports the GPL code — must be released under GPL too.
For distributed software, this means open-sourcing your entire codebase. Not just the plugin integration — everything it touches.
A nuance: standard GPL has a "SaaS loophole" — if you only run the software on your own servers and never distribute it, GPL's copyleft doesn't trigger. AGPL (Affero GPL) closes this loophole explicitly. But if you're shipping code to customers — on-premise deployments, plugins, SDKs — GPL's full copyleft applies.
GPL is designed to ensure software freedom. If you see GPL or AGPL on a dependency, understand the implications before integrating.
The Broader Pattern in AI
This isn't just about one NVIDIA project. The AI ecosystem has a licensing problem.
Model weights have their own licenses — Llama has the Meta Community License, Mistral has Apache-2.0 on some models, proprietary on others. Training data has implicit licenses that may conflict with the model license. And the code that orchestrates models — the agents, the pipelines, the deployment scripts — has yet another license.
A single AI product can involve three or more different licensing regimes:
You need to audit all of them. Not just the code you write, but every component you deploy.
How the AI Industry Is Evolving
There's a clear trend: the AI ecosystem is moving toward more permissive licensing. Major players are releasing infrastructure under Apache-2.0. This isn't altruism — it's strategy. Open-source infrastructure creates lock-in at the model and service layer.
The practical implication: the window for proprietary AI infrastructure is closing. If you're building a commercial product on top of AI, bet on Apache-2.0 components where possible. They're more sustainable, more forkable, and more likely to receive community contributions.
The Checklist
Before you fork any AI project for commercial use:
- Read the root
LICENSEfile — is it Apache-2.0, MIT, GPL, or proprietary? - Scan all SPDX headers — do they match the root license?
- Check
NOTICEfile for additional attribution requirements - Verify patent grants if the project involves patented algorithms
- Check model licenses separately from code licenses
- Check embedding model licenses — some "open" models have restrictive inference licenses
- Document your findings before writing any code
Five minutes of due diligence. Or weeks of rewriting. Your choice.
I'm Mehmet Gökçe. I run MEMOTECH, a Swiss IT consultancy based in St. Gallen, and I've been shipping integrations since 1998. These days I help DACH companies evaluate AI projects, including the licensing and compliance questions that decide whether a demo becomes a product.
If you're forking an AI repo and the SPDX headers feel murky, get in touch.
Part 4 of the Open-Source Commerce-AI series — "Why Agentic Commerce Will Reshape Shopware" — is publishing on memotech.ch. Subscribe to the MEMOTECH Newsletter to catch it.
Series Navigation:
- Part 1: Connecting an Upstream Multi-Agent Blueprint to Shopware 6
- Part 2: Swapping Llama 3.1 70B for Llama 4 Maverick
- Part 3: What I Learned Auditing the Upstream Open-Source Licensing (you are here)
- Part 4: Why Agentic Commerce Will Reshape Shopware (next)
This piece was originally published on Substack (m3mo Bytes) on April 15, 2026. The canonical version lives here on memotech.ch.
Update — May 5, 2026: MEMOTECH consolidated to pure Apache-2.0
Three weeks after this post argued for the discipline of license boundaries, MEMOTECH consolidated memotech-agentic-commerce from the hybrid setup described above (Apache-2.0 base + LicenseRef-MEMOTECH-Proprietary extension layer) to pure Apache-2.0 throughout (commit 8b84edd on the Bitbucket origin).
The architectural advice in this post still stands. Hybrid licensing is a legitimate path; the discipline of documenting license boundaries on day one is the lesson, regardless of which path you pick. The hybrid layer in our case proved over-engineered for our actual moats — domain expertise, customer relationships, authority through Reality-Check stance — none of which are protected by code secrecy. A Reality-Check posture in our public content is also internally inconsistent with treating our own stack as a black box, so we're aligning with the Build-in-Public default.
For the full pivot rationale and Tier-3 architecture trade-offs (hybrid vs. pure-OSS-plus-services), see the companion German Reality-Check article Agentic Commerce für DACH-Händler 2026.

Mehmet Gökçe
Founder & CEO
Gründer von MEMOTECH mit über 28 Jahren Erfahrung. Spezialisiert auf E-Commerce-Lösungen und digitale Transformation für Schweizer KMU.